Back-End Architecture
By iCareer Climber Team on 6 July 2018
[1] The Backend Application
The backend is a Flask application whose primary purpose is to accept job description inputs and output job similarity scores using the model. This allows us to serve up model results for consumption by the frontend application.
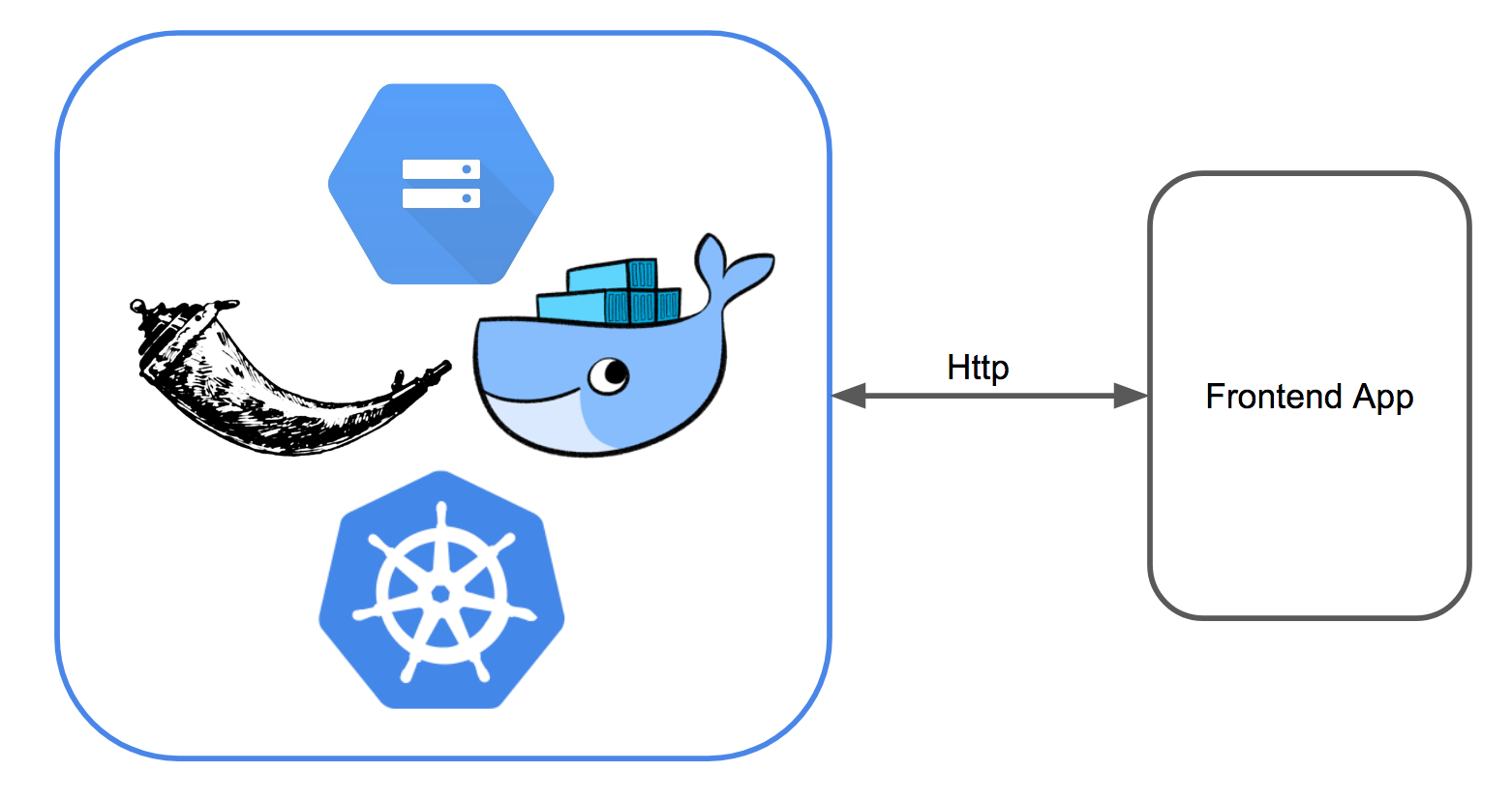
The application is built as a docker container which can easily be tested locally and then uploaded to Google Cloud Container Registry and deployed to a Google Cloud cluster with Kubernetes.
The models are stored in a Google Cloud Storage bucket, which is mounted to the application container using FUSE. The models are stored as pickled Scikit Learn models which can be loaded into the Flask application.
Next Steps
- Serve data for visualizations through api
- Add processes to automate scraping and data procoessing
- Store data received from front end for use in updating of models
[2] The API Requests
The backend is a basic REST api which accepts and serves JSON data.
Job similarity model:
$ curl -XPOST -H 'Content-Type: application/json' -d '{"experience":[{"description": "organizing projects with agile and scrum methodologies"}]}' 35.230.26.112/model/similar_jobs | python -m json.tool | head -22
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7535 100 7445 100 90 8638 104 --:--:-- --:--:-- --:--:-- 8636
{
"results": [
{
"probability": 0.24560086752139812,
"title": "technical project manager"
},
{
"probability": 0.09362546705168302,
"title": "quality assurance engineer"
},
{
"probability": 0.07340485510020563,
"title": "quality assurance analyst"
},
{
"probability": 0.05443605668438692,
"title": "ux engineer"
},
{
"probability": 0.05370892876346319,
"title": "program manager"
},
Top skills model
$ curl 35.230.26.112/model/skills/data%20scientist | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 501 100 501 0 0 20293 0 --:--:-- --:--:-- --:--:-- 21782
{
"results": [
"learning model predict",
"utilize machine learning",
"time series model",
"random forest svm",
"market basket analysis",
"forest gradient boosting",
"http github com",
"principal component analysis",
"using python sql",
"data analysis data",
"using logistic regression",
"structure unstructured data",
"large data set",
"various data source",
"learning predictive analytics",
"language processing nlp",
"using kmeans clustering",
"learning algorithm python",
"data science bootcamp",
"amazon web service"
]
}